
在复杂问题解决与高阶思考的场景中,GPT、Claude、Gemini等国外AI工具为何成为团队的默认选择?本文从语料质量、算力策略、人才环境和产品目标四个维度,深度剖析中外AI产品的本质差异,揭示中文大模型在通用推理能力上的结构性挑战与突围路径。

在真实的工作场景中,有一个现象其实并不难观察:
当问题开始变复杂、讨论需要不断发散,或者要把一个模糊的想法逐步推演成清晰方案时,团队默认使用的,往往是 GPT、Claude、Gemini这一类工具。
很少有人会专门解释原因,但这种选择,在产品和研发的日常协作中,已经悄然形成了一种“不成文的共识”。
我自己的工作习惯也并不例外。写方案、拆结构、梳理复杂信息——这些工具几乎都深度参与其中。
这不禁让我思考:为什么在真正需要“动脑”的高阶工作中,大家会更自然地选择这些工具?
也正是这个问题,促使我反过来拆解中外 AI 产品之间的深层差异:这些差异究竟来自哪里?
一、语料的差异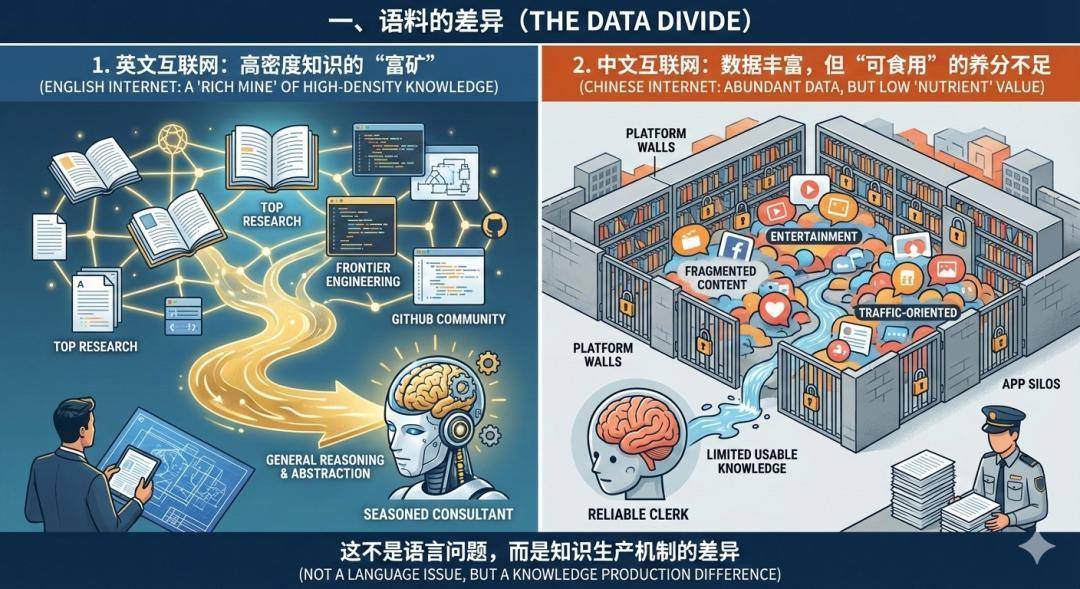
大模型的能力,本质上取决于它在预训练阶段“读过什么书”。
1. 英文互联网:高密度知识的“富矿”我们必须承认一个现实:
顶级科研论文前沿工程实践成熟的编程社区(如 GitHub)这些构成了高密度、可自由组合的通用知识体系,长期沉淀在英文互联网中。它们是训练“通用推理与抽象能力”的最佳养料。
2. 中文互联网:数据丰富,但“可食用”的养分不足中文世界并不缺数据,甚至在金融、政务、制造等垂直领域,我们拥有全球最丰富的行业数据。
但真正的问题在于:
高质量数据大量被锁在平台和 App 的“围墙”里,难以流动;
可公开使用的数据中,娱乐化、营销化、碎片化内容占比过高;知识生产更偏向“流量导向”,而非“长期积累”。结果不是“中文不行”,而是可用于训练“通用推理”能力的高密度语料相对稀缺。
这直接体现在使用体验上:
在复杂推理、方案生成时,国外模型更像一位“见多识广的资深顾问”;
而国内模型,往往更像一位“熟练、可靠的文书助手”。
这不是语言问题,而是知识生产机制的差异。
二、算力的差异如果说语料决定了模型的“见识”,那么算力和硬件则决定了模型的“成长方式”。
1. 国外路线:规模优先,用资源换可能性以 OpenAI、Anthropic 为代表的厂商,长期采取的是“大力出奇迹”的策略:
这是一种“用资源换可能性”的豪赌,目标是冲击智能的上限。
2. 国内路线:效率优先,用算法换成本受客观条件限制,国内厂商更强调“精打细算”:
算力效率
成本控制
工程优化
比如 2025 年初引发热议的 DeepSeek,就是通过 MoE 等工程与算法创新,用显著更低的算力成本,实现了极高的性能水平。这无疑是值得尊重的工程智慧。
3. 一个不可回避的取舍但必须承认,长期极致的“精打细算”,可能会限制模型去探索那些最烧钱、最不确定的通用智能边界。
这并非能力高低,而是目标函数不同:
国外:更多在追求“智能的上限”;国内:更关注“可交付、可控、可规模化”的智能。三、人才的差异如果翻看全球顶级 AI 团队的成员名单,你会发现一个熟悉的现象:
华人工程师、研究员的占比极高。
这本身就说明,人才从来不是问题。真正的差异,在于环境对“失败”的容忍度。
在国外:一个模型方向失败 ≠ 职业失败。资本愿意用长周期去赌未来。在国内:技术探索往往需要尽快证明 ROI 。一次重大失败,可能直接影响团队甚至公司的生存。这种环境差异,天然更适合:
国外:破坏式、从 0 到 1 的探索;国内:成熟技术的工程化、产品化与规模落地。这并非价值判断,而是现实约束。
四、目标的差异在反思“国外模型更好用”时,有一个前提经常被忽略:
很多国内 AI 产品,从诞生的第一天起,目标就不是“陪你思考”,而是“帮你少出错”。
从产品目标看,国内大量 AI 产品的核心诉求是:
这会自然导向:
而我们为 Claude、Gemini 付费,本质上是为另一件事买单:
认知扩展与不确定性价值。
这并不是模型能力单一维度的差距,而是产品设计取向的不同结果。
五、有些坑必须踩,有些路必须走回头看中国互联网的发展路径,我们确实曾跳过一些阶段:
没有长期沉淀 PC 时代的开放知识网络
直接进入移动互联网与平台化红利
大模型的出现,只是把这些“历史路径差异”重新放大。
有些坑必须踩,有些路必须走。时间,依然是技术最公平的变量。
写在最后以上只是我作为一名从业者的个人思考,视角有限,也可能存在偏差。
如果把“是否愿意付费”当作一个真实的用户行为指标,那么它背后的原因,值得每一个国内 AI 从业者冷静拆解。
欢迎在评论区留言讨论。
本文由 @产品不正经 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
传金所配资提示:文章来自网络,不代表本站观点。



